Playground de Geração de Texto
O playground de geração de texto do SipPulse AI permite testar e comparar o desempenho dos modelos de linguagem natural disponíveis na plataforma. Este ambiente interativo segue o formato de chat, facilitando a simulação de interações e a avaliação das respostas dos modelos.
Funcionalidades Principais
Seleção de Modelos
No playground, você pode escolher entre diversos modelos de geração de texto disponíveis na plataforma. Cada modelo pode ter parâmetros específicos, que são automaticamente exibidos quando o modelo é selecionado.
Parâmetros de Configuração
Ao selecionar um modelo, o playground apresenta os parâmetros disponíveis para ajuste. Esses parâmetros podem incluir:
- Temperatura: Controla a aleatoriedade das respostas do modelo. Valores mais baixos tornam a saída mais determinística, enquanto valores mais altos aumentam a diversidade.
- Máximo de Tokens: Define o número máximo de tokens na resposta gerada pelo modelo.
- Top P: Aplica amostragem de núcleo para limitar a escolha de tokens àqueles que compõem a maior parte da probabilidade de massa.
- Top K: Limita a seleção de tokens aos
Ktokens mais prováveis. Um valor menor reduz a diversidade, enquanto um valor maior aumenta a diversidade. - Penalidade por Frequência: Penaliza novos tokens com base na sua frequência existente no texto gerado até o momento, reduzindo a repetição.
- Penalidade por Presença: Penaliza novos tokens com base na presença deles no texto gerado até o momento, incentivando a introdução de novos tópicos.
Mensagem do Sistema
A mensagem do sistema (System Message) é usada para definir o comportamento do modelo e o contexto inicial. Esta mensagem é opcional, mas pode ser muito útil para orientar o modelo sobre como responder às mensagens subsequentes.
Execução do Teste
Após ajustar os parâmetros e configurar a mensagem do sistema, você pode iniciar o teste clicando no botão Run. O modelo processará as entradas e exibirá as respostas na lista de mensagens como "Assistant".
Interação Contínua
Você pode adicionar e remover mensagens conforme necessário para experimentar como o modelo se comporta em conversas mais longas. Isso permite avaliar a consistência e a capacidade do modelo de manter o contexto ao longo de uma interação.
Visualização de Código
O playground inclui um botão Ver Código, que mostra como integrar o modelo e os parâmetros testados em suas próprias aplicações. O código de integração pode ser visualizado em diferentes linguagens, incluindo Curl, Python e JavaScript.
Exemplo de Uso
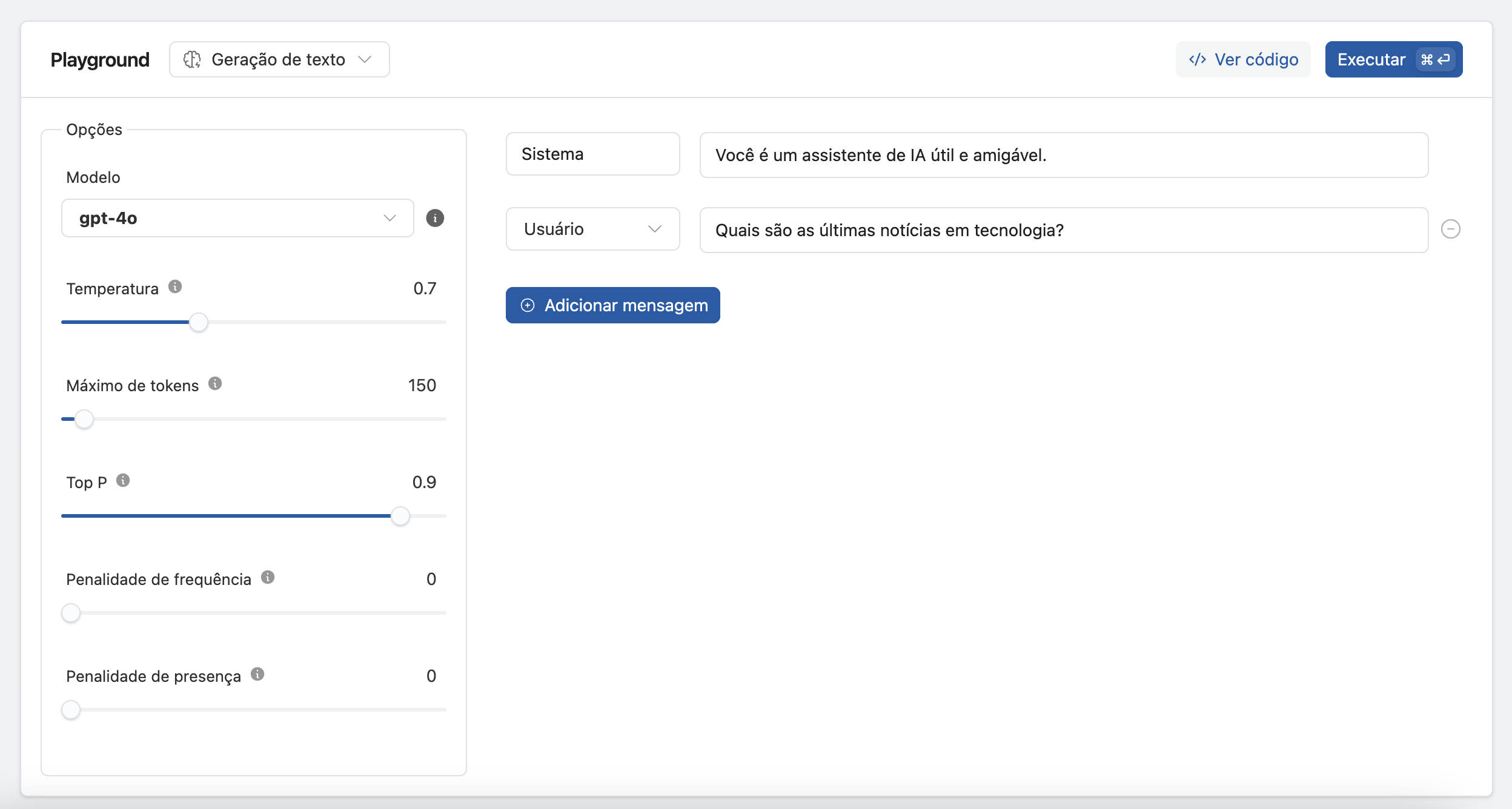
Vamos supor que você queira testar o modelo gpt-4o com uma configuração específica:
- Selecione
gpt-4ono menu de modelos. - Ajuste os Parâmetros:
- Temperatura: 0.7
- Máximo de Tokens: 150
- Top P: 0.9
- Mensagem do Sistema: "Você é um assistente de IA útil e amigável."
- Mensagem do Usuário: "Quais são as últimas notícias em tecnologia?"
- Execute o Teste: Clique em
Executarpara ver a resposta do modelo na lista de mensagens como "Assistente". - Adicione mais Mensagens: Continue a interação adicionando novas mensagens para ver como o modelo responde em uma conversa prolongada.
- Ver Código: Obtenha o código de integração clicando em
Ver Códigoe escolha a linguagem de sua preferência (Curl, Python ou JavaScript).
curl -X 'POST' \
'https://api.sippulse.ai/v1/llms/completion' \
-H 'Content-Type: application/json' \
-H 'api-key: $SIPPULSE_API_KEY' \
-d '{
"messages": [
{
"role": "system",
"content": "Você é um assistente de IA útil e amigável."
},
{
"role": "user",
"content": "Quais são as últimas notícias em tecnologia?"
}
],
"model": "gpt-4o",
"temperature": 0.7,
"max_tokens": 150,
"top_p": 0.9
}'import requests
url = 'https.//sippulse.ai/v1/llms/completion'
method = 'POST'
headers = {
'Content-Type': 'application/json',
'api-key': '$SIPPULSE_API_KEY',
}
data = json.dumps({"messages":[{"role":"system","content":"Você é um assistente de IA útil e amigável."},{"role":"user","content":"Quais são as últimas notícias em tecnologia?"}],"model":"gpt-4o","temperature":0.7,"max_tokens":256,"top_p":0.9})
response = requests.request(method, url, headers=headers, data=data)
print(response.text)const url = new URL("https.//sippulse.ai/v1/llms/completion");
const fetchOptions = {
method: "POST",
headers: {
"Content-Type": "application/json",
"api-key": "$SIPPULSE_API_KEY",
},
body: {
messages: [
{
role: "system",
content: "Você é um assistente de IA útil e amigável.",
},
{ role: "user", content: "Quais são as últimas notícias em tecnologia?" },
],
model: "gpt-4o",
temperature: 0.7,
max_tokens: 150,
top_p: 0.9,
},
};
fetch(url, fetchOptions)
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error("Error:", error));Conclusão
O playground de geração de texto é uma ferramenta poderosa para testar e comparar modelos de IA, permitindo uma configuração detalhada e a visualização em tempo real dos resultados. Utilize essa funcionalidade conhecer e comparar as soluções de linguagem natural e integrar facilmente os modelos testados em suas aplicações.