Text Generation
The SipPulse AI text generation playground allows you to test and compare the performance of natural language models available on the platform. This interactive environment follows a chat format, making it easy to simulate interactions and evaluate model responses.
Key Features
Model Selection
In the playground, you can choose from various text generation models available on the platform. Each model may have specific parameters, which are automatically displayed when the model is selected.
Configuration Parameters
When selecting a model, the playground presents the available parameters for adjustment. These parameters may include:
- Temperature: Controls the randomness of the model's responses. Lower values make the output more deterministic, while higher values increase diversity.
- Max Tokens: Defines the maximum number of tokens in the generated model response.
- Top P: Applies nucleus sampling to limit the choice of tokens to those that make up the majority of the probability mass.
- Top K: Limits token selection to the top
Kmost probable tokens. A lower value reduces diversity, while a higher value increases diversity. - Frequency Penalty: Penalizes new tokens based on their existing frequency in the generated text so far, reducing repetition.
- Presence Penalty: Penalizes new tokens based on their presence in the generated text so far, encouraging the introduction of new topics.
System Message
The system message is used to define the model's behavior and initial context. This message is optional but can be very useful in guiding the model on how to respond to subsequent messages.
Test Execution
After adjusting the parameters and configuring the system message, you can start the test by clicking the Run button. The model will process the inputs and display the responses in the message list as "Assistant".
Continuous Interaction
You can add and remove messages as needed to experiment with how the model behaves in longer conversations. This allows you to evaluate the model's consistency and ability to maintain context throughout an interaction.
Code Visualization
The playground includes a View Code button, which shows how to integrate the tested model and parameters into your own applications. The integration code can be viewed in different languages, including Curl, Python, and JavaScript.
Usage Example
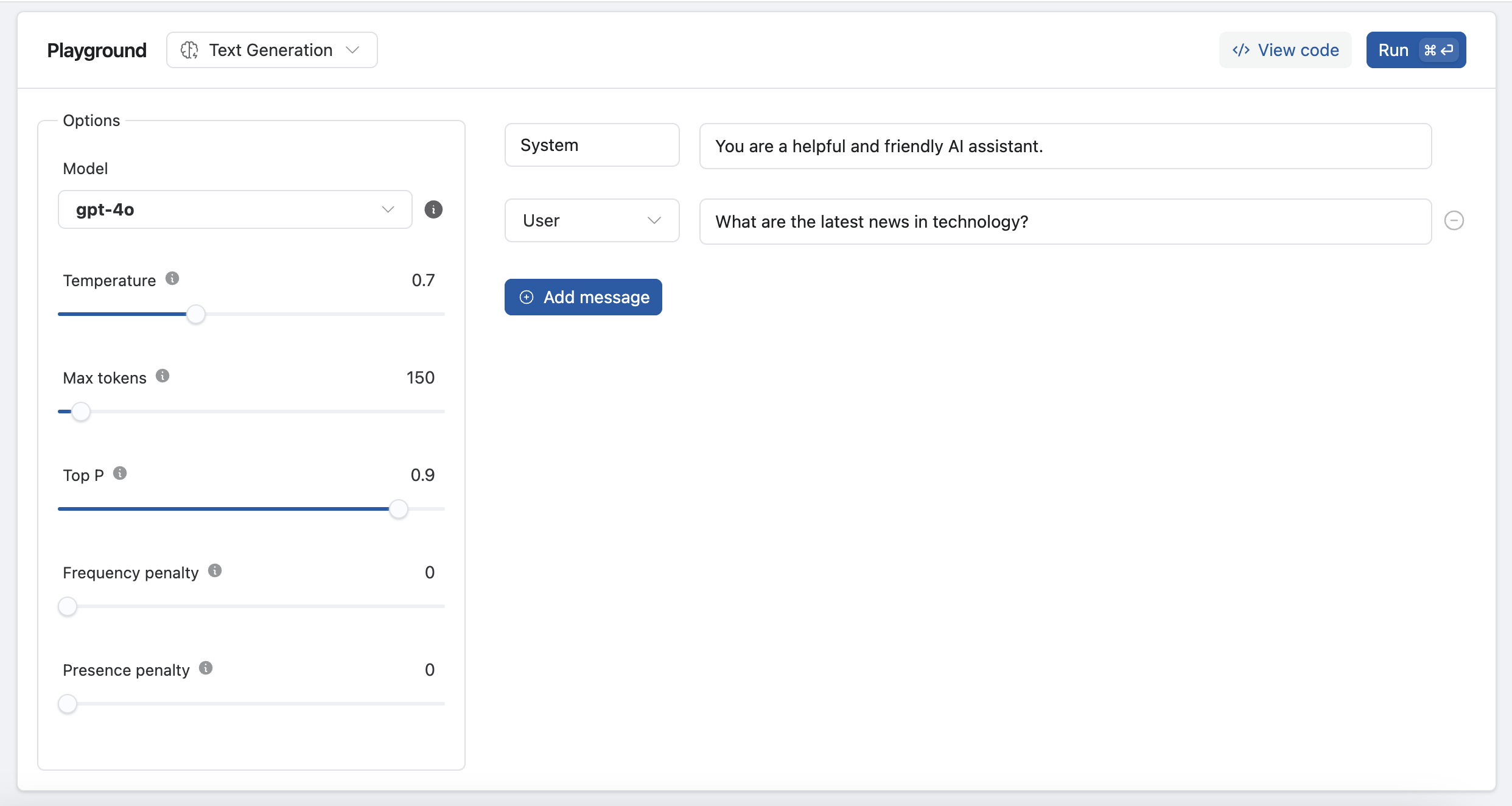
Let's suppose you want to test the gpt-4o model with a specific configuration:
- Select
gpt-4ofrom the model menu. - Adjust the Parameters:
- Temperature: 0.7
- Max Tokens: 150
- Top P: 0.9
- System Message: "You are a helpful and friendly AI assistant."
- User Message: "What are the latest news in technology?"
- Run the Test: Click
Runto see the model's response in the message list as "Assistant". - Add more Messages: Continue the interaction by adding new messages to see how the model responds in an extended conversation.
- View Code: Get the integration code by clicking
View Codeand choose your preferred language (Curl, Python, or JavaScript).
curl -X 'POST' \
'https://api.sippulse.ai/v1/llms/completion' \
-H 'Content-Type: application/json' \
-H 'api-key: $SIPPULSE_API_KEY' \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful and friendly AI assistant."
},
{
"role": "user",
"content": "What are the latest news in technology?"
}
],
"model": "gpt-4o",
"temperature": 0.7,
"max_tokens": 150,
"top_p": 0.9
}'import requests
url = 'https.//sippulse.ai/v1/llms/completion'
method = 'POST'
headers = {
'Content-Type': 'application/json',
'api-key': '$SIPPULSE_API_KEY',
}
data = json.dumps({"messages":[{"role":"system","content":"You are a helpful and friendly AI assistant."},{"role":"user","content":"What are the latest news in technology?"}],"model":"gpt-4-turbo-2024-04-09","temperature":0.7,"max_tokens":150,"top_p":0.9})
response = requests.request(method, url, headers=headers, data=data)
print(response.text)const url = new URL("https.//sippulse.ai/v1/llms/completion");
const fetchOptions = {
method: "POST",
headers: {
"Content-Type": "application/json",
"api-key": "$SIPPULSE_API_KEY",
},
body: {
messages: [
{
role: "system",
content: "You are a helpful and friendly AI assistant.",
},
{ role: "user", content: "What are the latest news in technology?" },
],
model: "gpt-3.5-turbo-0125",
temperature: 0.7,
max_tokens: 150,
top_p: 0.9,
},
};
fetch(url, fetchOptions)
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error("Error:", error));Conclusion
The text generation playground is a powerful tool for testing and comparing AI models, allowing for detailed configuration and real-time result visualization. Use this functionality to explore and compare natural language solutions and easily integrate the tested models into your applications.